Implementation of a Single RRPP Ring (When the Ring is Faulty)
Implementation of a Single RRPP Ring
In Figure 1, the link between SwitchA and SwitchB fails. SwitchA and SwitchB are transit nodes on the ring.
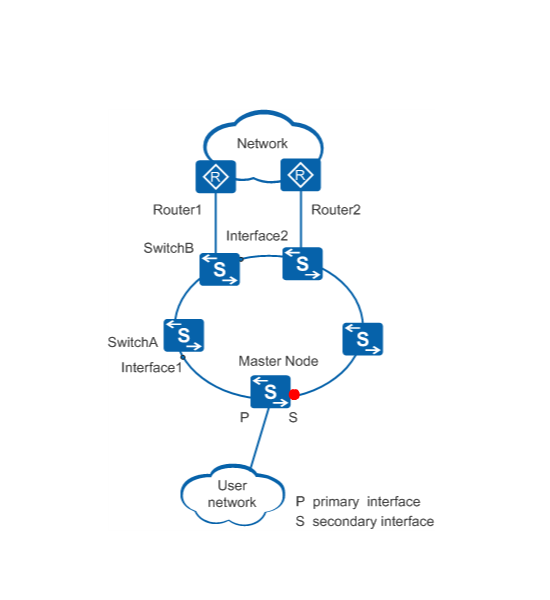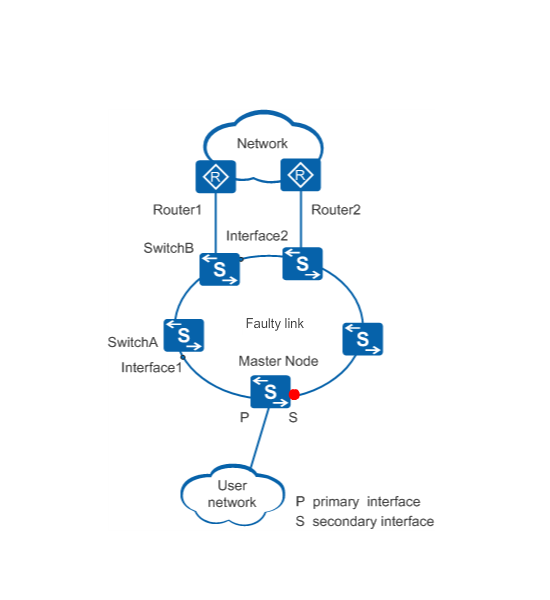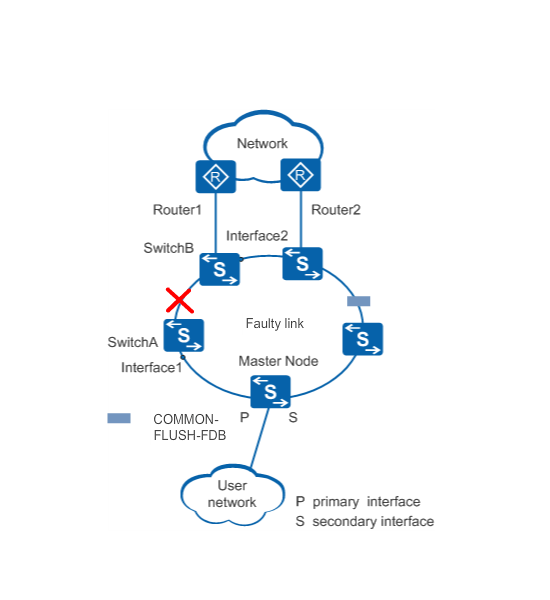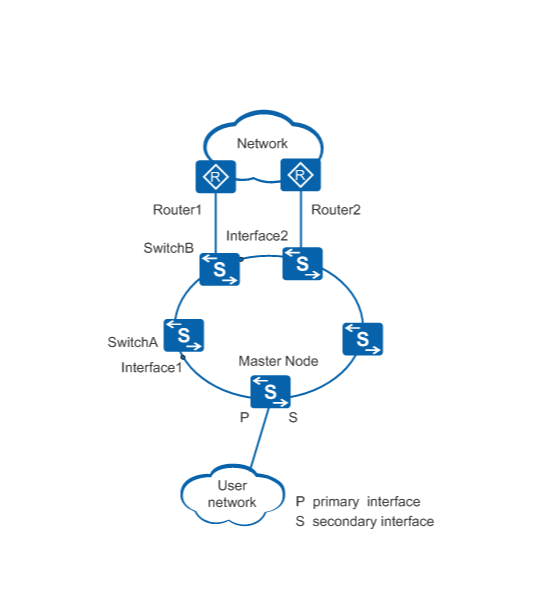
When SwitchA and SwitchB detect the link failure, they send LinkDown packets to the master node from Interface1 and Interface2 respectively.
Upon receiving a LinkDown packet, the master node changes from Complete state to Failed state and unblocks the secondary interface so that data packets can pass through.
When the network topology changes, the master node updates the forwarding entries to ensure correct packet forwarding. In addition, the master node sends a Common-Flush-FDB packet from the primary and secondary interfaces to request that all transit nodes update the forwarding entries.
Fault Detection and Processing
Faults on a ring can be detected in the following two ways:
LinkDown notification mechanism
Nodes on an RRPP ring monitor the link status of their interfaces. If a fault occurs on a link, the status of the interface directly connected to the link becomes Down. Upon detecting the Down state, the node immediately takes the following measures:
- If the primary interface on the master node is Down, the master node detects the link fault and immediately unblocks the secondary interface. In addition, the master node sends a Common-Flush-FDB packet from the secondary interface to request that all the transit nodes on the ring update their MAC address entries and ARP entries.
- If the interface on a transit node is Down, the node sends a LinkDown packet from its interface in Up state to the master node. When receiving the LinkDown packet, the master node changes to Failed state and unblocks its secondary interface. When the network topology changes, the master node must update its MAC address entries and ARP entries to prevent incorrect packet forwarding. In addition, the master node sends a Common-Flush-FDB packet from its primary and secondary interfaces to request that all transit nodes update their MAC address entries and ARP entries.
Polling mechanism
If the LinkDown packet is lost during transmission, the polling mechanism is used on the master node.
The master node periodically sends Hello packets from its primary interface. The packets are then transmitted through all transit nodes on the ring. If the secondary interface on the master node does not receive the Hello packet from the primary interface in the specified period, the master node considers the ring faulty. The fault is processed in the same way as a fault actively reported by a transit node. The master node changes to Failed state and unblocks the secondary interface. In addition, the master node sends a Common-Flush-FDB packet from its primary and secondary interfaces to request that all transit nodes update their MAC address entries and ARP entries.
The LinkDown notification mechanism processes faults more quickly than the polling mechanism, allowing RRPP to implement fast link switchover and convergence.